MCIR
 |
 |
 |
 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
MSA
 |
 |
 |
 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
NO
 |
 |
 |
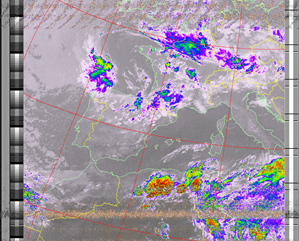 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
HVCT
 |
 |
 |
 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
JF
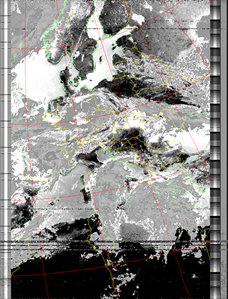 |
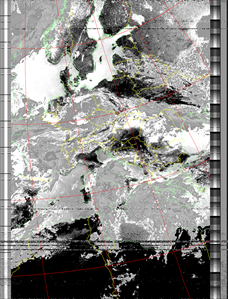 |
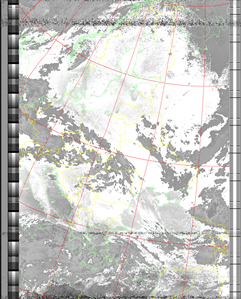 |
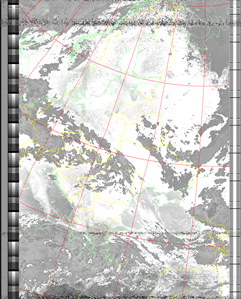 |
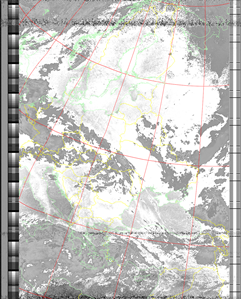 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
Thermal
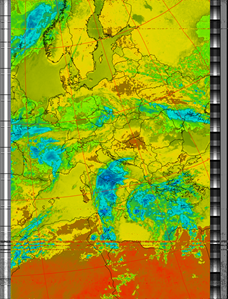 |
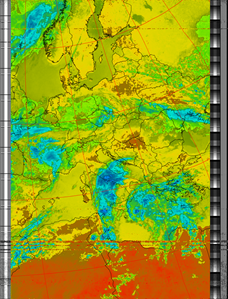 |
 |
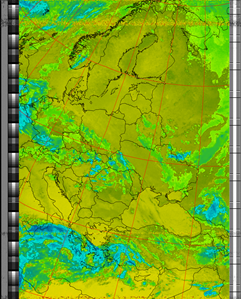 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |
SEA
 |
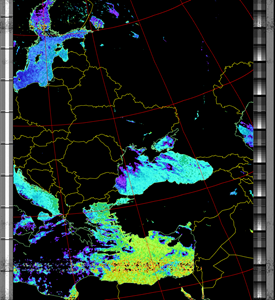 |
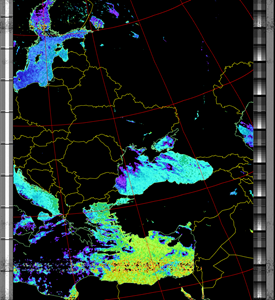 |
 |
 |
| 16 Aug 2025 10:47:21 GMT (NOAA 18) | 16 Aug 2025 09:06:56 GMT (NOAA 18) | 16 Aug 2025 06:49:58 GMT (NOAA 15) | (NOAA) | (NOAA) |